XPath Query
Il Task XPath Query è uno strumento specializzato per estrarre dati da un documento XML. Prende in input un testo XML proveniente da un Task precedente e applica un'espressione XPath (XML Path Language) per selezionare nodi o valori specifici all'interno di quel documento.
È un Task fondamentale per elaborare le risposte di chiamate SOAP, analizzare file di configurazione XML o estrarre informazioni da qualsiasi dato strutturato in formato XML.
1. Configurazione
La configurazione si concentra sulla definizione dell'espressione di ricerca e sulla gestione opzionale dei namespace.
- XML Content: il contenuto documento XML da cui si vogliono estrarre dati.
- XPath Expression: Il cuore del Task. In questo campo va inserita l'espressione XPath che definisce quali elementi si desidera selezionare dal documento XML.
- Namespaces (non obbligatori): Questa sezione risulta fondamentale nell’elaborazione di documenti XML che fanno uso di namespace, definiti tramite attributi quali
xmlnsoxmlns:prefix.
2. Esempio di Utilizzo (Senza Namespace)
Consideriamo un file XML semplice, come quello di una libreria, che non utilizza namespace:
<?xml version="1.0" encoding="UTF-8"?>
<libreria>
<libro id="1">
<titolo>Il Signore degli Anelli</titolo>
<autore>J.R.R. Tolkien</autore>
<anno>1954</anno>
</libro>
<libro id="2">
<titolo>1984</titolo>
<autore>George Orwell</autore>
<anno>1949</anno>
</libro>
<libro id="3">
<titolo>Il Nome della Rosa</titolo>
<autore>Umberto Eco</autore>
<anno>1980</anno>
</libro>
</libreria>
Obiettivo: Estrarre solo i titoli dei libri pubblicati dopo il 1950.
Configurazione del Task:
- XPath Expression: Si inserisce l'espressione: /libreria/libro[anno > 1950]/titolo
- Namespaces: La sezione viene lasciata vuota.
Risultato Atteso: Il parametro result del Task conterrà un nuovo documento XML con i due titoli che soddisfano la condizione:
<titolo>Il Signore degli Anelli</titolo>
<titolo>Il Nome della Rosa</titolo>
3. Esempio di Utilizzo (Con Namespace)
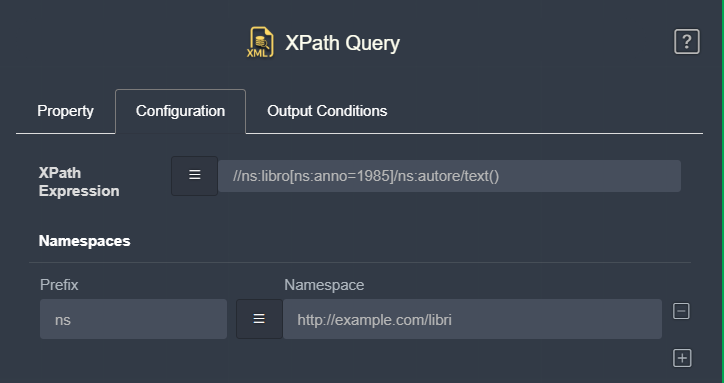
Mentre l’esempio precedente è valido per XML semplici, questo task gestisce anche XML in cui gli elementi appartengono ad un namespace predefinito, richiedendo di associare manualmente un prefisso al namespace per poter utilizzare correttamente XPath.
Consideriamo una versione dell'XML che utilizza un namespace:
<libreria xmlns="http://example.com/libri">
<libro>
<anno>1321</anno>
<titolo>La Divina Commedia</titolo>
<autore>Dante Alighieri</autore>
</libro>
<libro>
<anno>1600</anno>
<titolo>Amleto</titolo>
<autore>William Shakespeare</autore>
</libro>
<libro>
<anno>1980</anno>
<titolo>Il Nome della Rosa</titolo>
<autore>Umberto Eco</autore>
</libro>
</libreria>
In questo caso, un'espressione XPath come /libreria/libro/titolo fallirebbe, perché i nodi non si chiamano "libreria" o "libro", ma sono qualificati dal namespace http://example.com/libri.
3.1 Uso Prefissi e Namespace
Se volessimo estrarre solo il titolo del libro pubblicato dopo il 1950, da questo XML con namespace, dobbiamo prima "insegnare" al Task cosa significa il prefisso che useremo (es. ns).
Nella sezione Namespaces, aggiungiamo una riga:
| Prefix | Namespace |
|---|---|
| ns | http://example.com/libri |
Ora possiamo scrivere l'espressione XPath utilizzando il prefisso che abbiamo registrato: //ns
3.2 Risultato Atteso
Il parametro result del Task conterrà un nuovo documento XML con il solo titolo che soddisfa la condizione, preservando il suo namespace originale:
<ns:titolo xmlns:ns="http://example.com/libri">Il Nome della Rosa</ns:titolo>
Se non viene impostato il prefisso e il namespace, il parametro resultconterrà invece un messaggio di errore: Warning: DOMXPath::query(): Undefined namespace prefix
Nota
Quando gli elementi XML hanno un prefisso esplicito:
Non è necessario associare manualmente un prefisso al namespace. Infatti, XPath può utilizzare direttamente il prefisso già presente (ns1) per individuare gli elementi, semplificando la scrittura delle query rispetto ai namespace predefiniti senza prefisso.
4. Parametri di Output
Il Task espone un unico Parametro di Output principale:
- result: Contiene il risultato della query XPath oppure un messaggio di errore.
- Se la query restituisce un singolo valore di testo semplice (es. il contenuto di un tag
<titolo>), il result conterrà direttamente quel valore come stringa. - Se la query restituisce uno o più nodi XML (strutture complesse), il result conterrà un nuovo documento XML ben formato contenente solo i nodi trovati.
- Se la query restituisce un singolo valore di testo semplice (es. il contenuto di un tag
- resultJson: rappresenta il risultato dell’esecuzione del task in formato JSON, includendo informazioni generali, configurazioni e dettagli sull’esecuzione.