XML to Table
- Task type: xml-to-table
Il Task XML to Table consente di importare i dati da un file XML con struttura tabellare e inserirli in una tabella di un database. La sua funzione è duplice: si connette a un database per scrivere fisicamente i dati e, allo stesso tempo, espone i dati importati come un Dataset per l'utilizzo da parte di Task successivi nel Workflow (come un Iterator). Questo Task lavora su un XML in ingresso fornito da un Task precedente (es. "Importa Testo").
1. Connessione database
In questa scheda si configurano tutti i parametri per stabilire la connessione al database di destinazione.
1.1 Tabella target
È possibile definire l’origine delle credenziali per la connessione:
- Manuale: consente l’inserimento manuale di tutti i dati della connessione e della tabella nei campi sottostanti.
- Environment: consente di utilizzare un ambiente di connessione preconfigurato. Selezionandone uno, i campi di autenticazione vengono compilati automaticamente.
1.2 Tipologia Database
Seleziona il tipo di database (DBMS) a cui connettersi. Le opzioni supportate includono:
- PostgreSQL
- SQL Server
- MySQL
- Oracle DB (usando Oracle si può scegliere tra SID e SERVICE)
1.3 Connessione SSL
Indica se la connessione al database deve avvenire tramite un canale sicuro.
1.4 Autenticazione
| Campo | Descrizione |
|---|---|
| Host | Indirizzo del server del database (es. localhost, 192.168.1.100). |
| Porta | Porta usata per la connessione (es. PostgreSQL: 5432, MySQL: 3306). |
| Nome DB | Nome del database a cui connettersi. |
| User | Nome utente per accedere al database. |
| Imposta Password | Apre una finestra per inserire la password in modo sicuro. |
1.5 Gestione tabella
Definisce come il task deve interagire con la tabella fisica nel database.
- Tabella target: determina l’azione da eseguire sulla tabella:
- Crea tabella: crea sempre una nuova tabella. L’operazione fallisce se esiste già una tabella con lo stesso nome.
- Crea tabella se non esiste: crea una nuova tabella solo se non esiste già una tabella con lo stesso nome.
- Tabella esistente: inserisce i dati in una tabella già presente. Per impostazione predefinita, i nuovi dati vengono aggiunti a quelli già presenti (Append). Attivando la checkbox Truncate Insert, la tabella viene svuotata prima di inserire i nuovi dati.
- Nome tabella target: nome della tabella da creare o in cui scrivere i dati (es.
utenti,prodotti,log_eventi).
2. Struttura tabellare
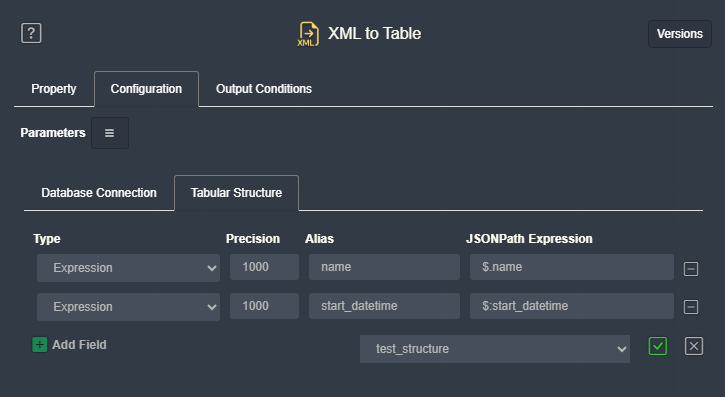
La scheda Struttura tabellare permette di definire i campi (colonne) della tabella e mappare ciascuna colonna con gli elementi del file XML di origine.
2.1 Campi disponibili
Ogni riga rappresenta una colonna della tabella. Per ciascun campo è possibile configurare:
| Campo | Descrizione |
|---|---|
| Tipo | Tipo di dato del campo. Valori disponibili: NUMERICO, STRINGA, DATA, DATA E ORA |
| Precisione | Per NUMERICO: numero massimo di cifre; per STRINGA: lunghezza massima |
| Alias | Nome effettivo della colonna nella tabella del database. Sarà questo il nome visibile nel DB. |
| Espressione JSONPath | Espressione JSONPath per estrarre il valore dal file XML di origine (es. $.persona.info.name) |
2.2 Gestione Table Structure
In basso a destra della Struttura tabellare sono presenti tre pulsanti:
| Pulsante | Azione |
|---|---|
| Salva | Salva la struttura definita |
| Importa | Importa una struttura esistente |
| Esporta | Esporta la struttura definita |
Questa funzionalità permette di salvare, esportare o riutilizzare le mappature, evitando la compilazione manuale dei campi e riducendo il rischio di errori.
Nota Tecnica
- Visibilità: Le strutture salvate nel sistema sono visibili esclusivamente all'utente che le ha create.
- Approfondimento: Per una descrizione dettagliata di tutte le opzioni e della logica di funzionamento, fare riferimento alla pagina Table Structure.
3. Esempio di configurazione
Per creare una tabella utenti con i seguenti campi:
| Tipo | Alias | Espressione JSONPath |
|---|---|---|
| STRINGA | name | $.user.info.name |
| STRINGA | $.user.info.email | |
| NUMERICO | age | $.user.info.age |
| STRINGA | city | $.address.city |
| DATA | registration_date | $.registration.date |
| DATA E ORA | registration_datetime | $.registration.datetime |
Il risultato di questa configurazione sarà la creazione di una tabella nel database con le colonne name, email, age, city, registration_date e registration_datetime (Alias) popolate con i valori estratti dal XML (Espressione JSONPath).
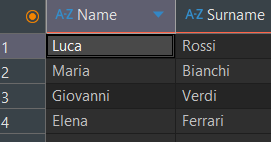
3.1 Alias con caratteri speciali o maiuscole
Se si vogliono usare lettere maiuscole, caratteri speciali o spazi nei nomi delle colonne, è necessario racchiudere l'Alias tra doppi apici (es. "Nome Utente").
| Tipo | Alias | Espressione JSONPath |
|---|---|---|
| STRINGA | “Name” | $.name |
| STRINGA | “Surname” | $.surname |
3.2 Risultato nel Database
4. Gestione di Strutture XML Annidate
Il Task XML to Table è in grado di gestire file XML che contengono elementi annidati, ovvero una gerarchia di dati all'interno del record principale. Invece di richiedere la creazione di tabelle separate (normalizzazione), il Task può serializzare l'intero blocco di dati annidato in un'unica colonna di testo, tipicamente in formato JSON.
Esempio Pratico
Consideriamo il seguente file XML di input, dove ogni <person> ha una lista annidata di <departments>:
<people>
<person>
<name>Luca</name>
<surname>Rossi</surname>
<departments>
<department>Marketing</department>
<department>Sales</department>
</departments>
</person>
<person>
<name>Maria</name>
<surname>Bianchi</surname>
<departments>
<department>HR</department>
</departments>
</person>
...
</people>
L'obiettivo è mappare ogni <person> a una riga della tabella, preservando l'elenco dei dipartimenti associati a ciascuna persona.
4.1 Configurazione nella "Struttura Tabellare"
Per ottenere questo risultato, la configurazione nella scheda "Struttura tabellare" sarà la seguente:
| Tipo | Precisione | Alias | Espressione JSONPath |
|---|---|---|---|
| String | 1000 | name | $.name |
| String | 1000 | surname | $.surname |
| String | 4000 | departments | $.departments |
Spiegazione:
- Le colonne name e surname sono mappate in modo diretto, poiché i loro valori sono elementi semplici (
<name>,<surname>). - Per la colonna departments, l'Expression è impostata su departments. Questo indica al Task di non cercare un singolo valore, ma di prendere l'intero contenuto del tag
<departments>per ogni persona. - Il Task converte automaticamente questo frammento XML nel suo equivalente JSON prima di inserirlo nella colonna del database.
4.2 Risultato nel Database
Applicando questa configurazione, il Task produrrà una tabella in cui la colonna departments contiene una stringa JSON che rappresenta la struttura annidata originale. Questo permette di conservare l'intera informazione gerarchica in un singolo campo di testo, pronto per essere eventualmente analizzato da altri strumenti o Task.
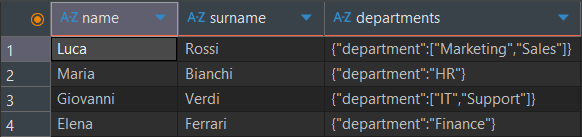
4.3 Estrazione di sotto-elementi con JSONPath
Se invece si volesse estrarre singoli elementi annidati, come ad esempio i nomi dei dipartimenti, è possibile utilizzare un’Espressione JSONPath specifica. Ad esempio:
| Tipo | Precisione | Alias | Espressione JSONPath |
|---|---|---|---|
| String | 1000 | name | $.name |
| String | 1000 | surname | $.surname |
| String | 1000 | department_names | $.departments.department[*].details.name |
Con questa configurazione, il Task XML to Table seleziona tutti i valori name presenti nell’array department e li inserisce nella colonna department_names del database, separandoli eventualmente con una virgola.
4.4 Risultato nel Database
| name | surname | department_names |
|---|---|---|
| Luca | Rossi | Marketing, Sales |
| Maria | Bianchi | HR |
Questo approccio consente di estrarre solo i dati necessari, senza serializzare l’intero blocco JSON, rendendo la tabella più facilmente interrogabile e utilizzabile in altri Task o report.
5. Parametri di Output
Una volta che il Task XML to Table ha completato l'elaborazione, espone un ricco set di parametri di output. Questi parametri non solo forniscono informazioni sull'esito dell'operazione, ma mettono anche a disposizione i dati elaborati in vari formati per i Task successivi.
- result: Fornisce lo stato complessivo dell'esecuzione del Task (es. "Success" o un messaggio di errore).
- targetTable: Restituisce il nome della tabella del database in cui i dati sono stati inseriti.
- rowCount: Indica il numero totale di righe che sono state inserite nella tabella di destinazione.
- DataExportCsv: Restituisce l'intero set di dati elaborato, formattato come testo in formato CSV (Comma-Separated Values).
- DataExportJson: Restituisce l'intero set di dati elaborato, formattato come una stringa JSON.
- Dataset: Questo parametro rappresenta il nome della colonna della tabella (Per es: name). È il parametro più importante per collegare questo Task ad un Iterator. Per accedere ai valori di una specifica colonna durante un'iterazione, si utilizza la sintassi Dataset.NomeColonna.
- DataColumn: Questo parametro permette di accedere all'intero contenuto di una colonna come un'unica entità (ad esempio, un array o una lista).
- DataColumn.NomeColonna: Restituisce tutti i valori della colonna “NomeColonna”. Per es: “Luca, Maria, Giovanni, Elena”
- resultJson: rappresenta il risultato dell’esecuzione del task in formato JSON, includendo informazioni generali, configurazioni e dettagli sull’esecuzione.
6. Esempio parametro resultJson
{
"id": 18679,
"name": "XML to Table",
"description": "",
"type": "xml-to-table",
"type_name": "XML to Table",
"type_description": "Import di un XML nel sistema",
"config": {
"db_host": "test",
"db_name": "TABLE_TEST;TrustServerCertificate=Yes",
"db_port": "1433",
"db_type": "sqlserver",
"db_user": "user_test",
"use_ssl": "Y",
"tab_name": "test_#>$$WORKFLOW_ID<#",
"tab_target": "E",
"db_password": "S1sp7LAv8jjvuZqoVuzCYA7YiaTzrJaF2h1VauGKDUI=",
"output_links": [
{
"to": "[TASK 1401_18899_60]",
"from": "[TASK 1401_18679_28]",
"text": "Condizione 21",
"color": "green",
"points": [
-1142.18563863061,
-657.1544319845046,
-1132.18563863061,
-657.1544319845046,
-1085.9861501254436,
-657.1544319845046,
-1085.9861501254436,
-780.3758165825338,
-1039.7866616202773,
-780.3758165825338,
-1029.7866616202773,
-780.3758165825338
],
"toPort": "left4",
"fromPort": "port_1401_18679_1",
"isTraversed": true
}
],
"tab_truncate": false,
"tablestructure": [
{
"field_name": "task_name",
"field_type": "string",
"field_value": "$.task_name",
"field_format": "",
"field_nullable": "Y",
"field_precision": "1000"
},
{
"field_name": "status",
"field_type": "string",
"field_value": "$.status",
"field_format": "",
"field_nullable": "Y",
"field_precision": "1000"
}
],
"connection_mode": "env",
"env_connection_name": "SqlServer_TEST",
"oracle_db_name_type": "0"
},
"run_info": {
"run_id": 1457111,
"start_datetime": "2026-03-19 15:52:02",
"end_datetime": "2026-03-19 15:52:02",
"start_epoch": 1773935522.274858,
"end_epoch": 1773935522.545901,
"duration": 0,
"status": "Completed",
"cmd_text": "",
"run_result": "Success",
"result_text": "3 righe inserite nella tabella test_1401",
"full_result_text": "3 righe inserite nella tabella test_1401"
},
"output_parameters": {
"rowCount": "3",
"exitStatus": "0",
"targetTable": "test_1401",
"DataExportCsv": "task_name;status\n\"Generate Summary\";pending\n\"Translate Text\";done\n\"Check Grammar\";running\n",
"DataExportJson": "[{\"task_name\":\"Generate Summary\",\"status\":\"pending\"},{\"task_name\":\"Translate Text\",\"status\":\"done\"},{\"task_name\":\"Check Grammar\",\"status\":\"running\"}]",
"Dataset.status": "status",
"DataColumn.status": "pending,done,running",
"Dataset.task_name": "task_name",
"DataColumn.task_name": "Generate Summary,Translate Text,Check Grammar"
}
}